
AI 導入の現場 — 6 業界の代表ケースをアーキテクチャで読む
Morgan Stanley の RAG・BMW の予知保全・Walmart の在庫最適化・Mayo Clinic の連合学習・GitHub Copilot・Klarna の 6 業界事例を、採用技術と効果指標、アーキテクチャの観点から整理して解説します。
TL;DR
- 金融(Morgan Stanley): GPT + RAG で 35 万件超の社内ナレッジを統合検索し、アドバイザの採用率は 98% に到達しました。
- 製造(BMW Plant Regensburg): 既存制御データだけで予知保全を組み、組立ラインの停止時間を 年 500 分 削減しています。
- 小売(Walmart): 時系列 ML・コンピュータビジョン・エージェントを束ねて在庫を多重最適化し、4,700 店舗 + EC を回しています。
- 医療(Mayo Clinic): Federated Learning(連合学習) で患者データを動かさずモデルだけを共有し、規制と協業を両立しています。
- CS / ソフト開発(Klarna・GitHub Copilot × Accenture): AI で大規模効率化が出る一方、Klarna は 2025 年に 部分的な人間再雇用 に踏み切るなど、効率と体験品質は別軸で測るべきだと示しています。
要点サマリ表
| 業界 | 事例 | 採用技術 | 期待効果 |
|---|---|---|---|
| 金融 | Morgan Stanley | GPT-4 + RAG + Whisper | アドバイザ採用率 98% |
| 製造 | BMW(Plant Regensburg) | センサーデータ + 異常検知 ML | 組立停止 年 500 分削減 |
| 小売 | Walmart | 時系列 ML + Vision + エージェント | Stockout 削減・回転率向上 |
| 医療 | Mayo Clinic + Google Cloud | Vertex AI + Federated Learning | 患者データを安全に院外共有 |
| ソフト開発 | GitHub Copilot × Accenture | LLM 補完 + IDE 統合 | PR マージ率 +15%、ビルド成功 +84% |
| CS | Klarna + OpenAI | LLM チャット + 多言語ルーティング | 月 230 万会話・解決時間 11→2 分 |
背景・経緯
ChatGPT 公開以降、AI 導入は「実験フェーズ」から「業務組み込みフェーズ」へ移行 しました。2022 年末までは PoC(Proof of Concept、概念検証)が大半で、業務 KPI と紐づかない実証が多くを占めていました。2023 年以降はベンダー各社の導入事例公開が急増し、2024-2025 年にかけて業界横断で「数字で測れる効果」を出した事例が揃ってきています。
事例公開数の増加には、AI 投資を社内外に説明する必要性が高まった という背景もあります。経営層が AI 予算を承認するには「他社で何が起きているか」のベンチマークが要求されます。そのため OpenAI / Anthropic / Microsoft / Google が顧客事例を競って公開し、採用技術と効果指標が同時に開示される機会が増えました。
ただし公開事例には マーケティング由来のバイアス も含まれます。導入企業とベンダー双方に「成功談として語る」インセンティブが働くため、数値を読むときは「公式 1 次情報」「業界レポート」「事後の方針転換報道」を分けて扱う必要があります。本記事は確定情報(BMW Press、GitHub Blog の RCT 等)を優先し、二次情報の数値は留保を付けます。
本記事で 6 業界(金融・製造・小売・医療・ソフトウェア開発・カスタマーサポート)を選んだのは、(1) 公開ソースの信頼性が比較的高い、(2) 数値の検証可能性がある、(3) 読者の業界関心が広く分布する の 3 軸からです。
本題の詳細
1. 金融 — Morgan Stanley の社内 RAG
事例: Morgan Stanley Wealth Management 業務: 35 万件超の社内ナレッジ文書をアドバイザが質問形式で検索 + 顧客面談録音の自動議事録化 採用技術: GPT-4 + RAG(Retrieval-Augmented Generation)(OpenAI Embeddings + Vector DB)+ Whisper(音声→テキスト)
Morgan Stanley は OpenAI と複数年の協業を進めており、社内向けに AI @ Morgan Stanley Assistant(ナレッジ検索)と Debrief(顧客面談の自動議事録)を展開しています。同社の発表では、Assistant のアドバイザ採用率は 98% に達し、ナレッジ検索の対象範囲が大幅に広がりました。
技術的には、社内文書を Embedding で意味ベクトル化して Vector DB に格納し、アドバイザの質問を同じ空間に投影して関連文書を抽出、その文書群を GPT-4 に渡して回答を生成する 典型的な RAG 構成 です。Debrief 側は Whisper で文字起こし → GPT-4 で要約・アクション抽出という構成で、面談後の事務作業時間を直接削っています。
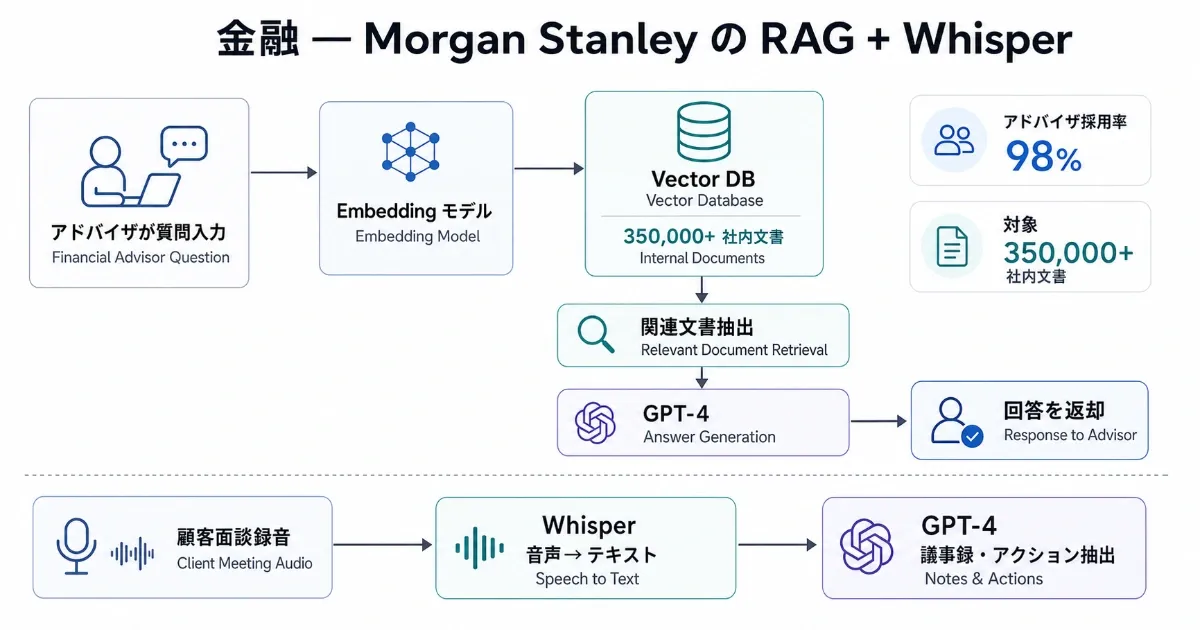
効果指標:
- アドバイザ採用率 98%(OpenAI 公式事例ページ)
- 回答可能ナレッジ範囲が大幅拡大(公開発表では 7K → 100K 単位の拡大が示されています)
注意点: 金融は機密性が高く、外部 API への送信にはオンプレ / 専用 VPC 等の構成が前提になります。コンプライアンス部門と握らずに進めると後から RAG 全体の再構築コストが発生します。
2. 製造 — BMW Plant Regensburg の予知保全
事例: BMW Group Plant Regensburg(独) 業務: 組立ライン搬送機構の異常を事前検知し、停止を回避 採用技術: 既存の制御コンピュータが収集する電力・動作データ を使った異常検知 ML(追加センサー不要)
BMW は 2023 年 11 月のプレスリリースで、既存制御系のデータをそのまま機械学習モデルに流して 故障の兆候を検知し、計画停止に置き換える 仕組みを公表しました。新規センサーを敷設せず、既存ハードのデータだけで実現している点が要諦です。
このアプローチは「AI のために大規模設備投資が必要」という固定観念を覆します。多くの製造現場には既に大量のセンサーログがあり、それを LLM ではなく古典的な時系列 ML(異常検知・回帰)に流すだけで投資対効果が出る、というのが事例の示唆です。

効果指標:
- 組立ライン停止時間 年 500 分削減(BMW Press 2023-11-27)
- 主要組立ラインの 約 80% に展開済み(同上)
注意点: 予知保全は故障モードを学習で捉えるため、データの質と「異常データの少なさ」のバランスが課題です。正常稼働ばかりのデータからは異常パターンを学べないため、過去の故障記録を整理する前処理が成否を分けます。
3. 小売 — Walmart の需要予測と在庫管理
事例: Walmart(米国 4,700 店舗 + EC) 業務: 在庫最適化、需要予測、店舗内棚センサーによるリアルタイム可視化 採用技術: 時系列 ML(需要予測)+ Computer Vision(棚センサー)+ エージェント(自動発注・配送調整)
Walmart はホリデーシーズンの在庫運用を AI 主導に切り替え、社内 Tech Blog で複数の構成要素を公開しています。需要予測モデルが店舗・SKU 単位で発注量を計算し、店舗内のビジョンシステムが棚の欠品状況を自動検知、エージェント層が補充計画と配送スケジュールを自律調整する 多重最適化スタック です。
ここでの「エージェント」は前回記事で扱った LLM ベースの自律エージェントとは別物で、ルールベース + ML 推論 + 業務フロー を統合した在庫管理エージェントです。生成 AI 文脈以前から存在する古典的なオペレーションズリサーチ(OR)の系譜が AI と統合されつつあります。
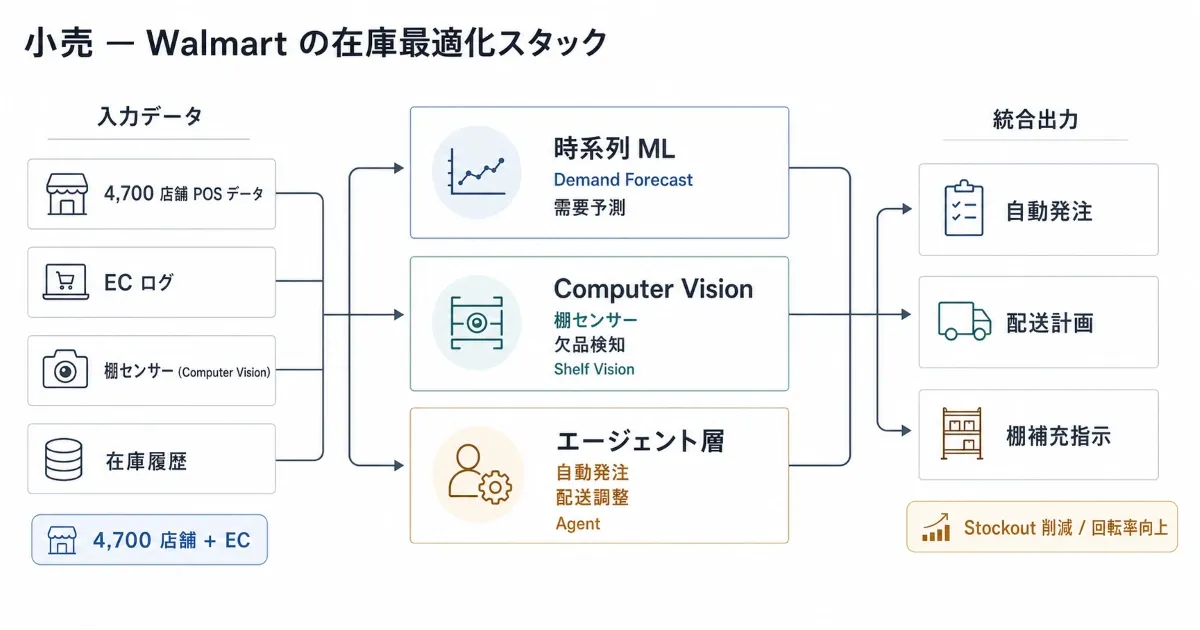
効果指標(業界レポート / 二次情報 ベース):
- Stockout 比率 5.5% → 3% 程度(業界レポートでは・(要検証))
- 過剰在庫 -15%(業界レポートでは・(要検証))
- 在庫回転率 8 → 10.5(業界レポートでは・(要検証))
注意点: 多重最適化は KPI 同士の競合 に陥りやすい構造です。例えば「欠品ゼロ」を強く最適化すると過剰在庫が増え、「在庫圧縮」を強くすると欠品が増えます。重み付けと監視ダッシュボードを最初に握っておかないと、効果計測すら難しくなります。
4. 医療 — Mayo Clinic の連合学習
事例: Mayo Clinic(米)+ Google Cloud 業務: CT / MRI 等の画像診断モデル開発、患者データを動かさずモデルを共同学習 採用技術: Google Cloud Vertex AI + Federated Learning(連合学習)(“Data under glass” 方式)
Mayo Clinic は Google Cloud との複数年契約で、患者の生データを Mayo の境界外に出さない 前提でのモデル開発体制を構築しています。これは医療規制(HIPAA 等)と協業の両立を狙った設計で、データではなく モデルの重みや勾配だけを交換 することで分散学習を成立させます。
連合学習は技術的には数年前から研究されていましたが、規制要件と運用負荷を許容できる組織 はごく一部に限られます。Mayo Clinic 規模の専門組織だからこそ運用できるアプローチで、すべての医療機関が同じ構成を取れるわけではない点に注意が必要です。
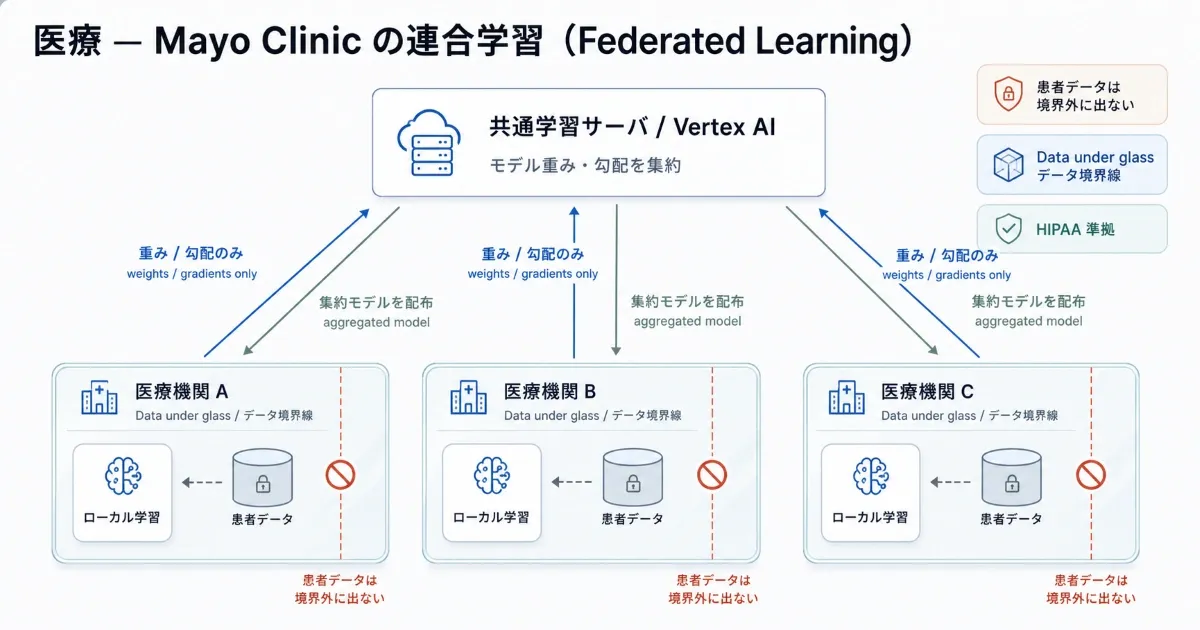
効果指標:
- 患者データを 院外に出さずに 外部パートナーとモデル共同開発
- de-identified(個人特定不可化)データでの院外協業を継続中
- 具体的な精度向上数値は乏しいため、「導入アプローチの特異性自体が成果」と読むのが妥当
注意点: 規制(HIPAA / FDA / 各国医療規制)と 医療責任の所在は依然として人間側 に残ります。AI が画像診断の補助をしても最終診断は医師の責任であり、その境界線が曖昧な構成を組むと法務リスクが急増します。
5. ソフトウェア開発 — GitHub Copilot × Accenture RCT
事例: Accenture 社内(GitHub Copilot 大規模 RCT) 業務: コード補完、PR レビュー支援、テストコード生成 採用技術: LLM コード補完(GPT-4 系) + IDE プラグイン
GitHub と Accenture は 2024 年 5 月 13 日、社内エンジニアを対象とした RCT(Randomized Controlled Trial、無作為化比較試験)の結果を公表しました。実験条件下での測定 であり、ベンダー試算ではなく 比較群を置いた厳密な評価 という点が他の生産性指標とは異質です。
公表値は次のとおりです: PR 数 +8.69%、PR マージ率 +15%、ビルド成功率 +84%、67% の開発者が 週 5 日以上 利用、開発者の 90% が「業務に充実感を覚える」と回答、95% が「コーディングを楽しく感じる」と回答。一方で、よく引用される 「タスク 55% 高速化」は別ラボ研究の数値で、本 RCT の値ではありません。
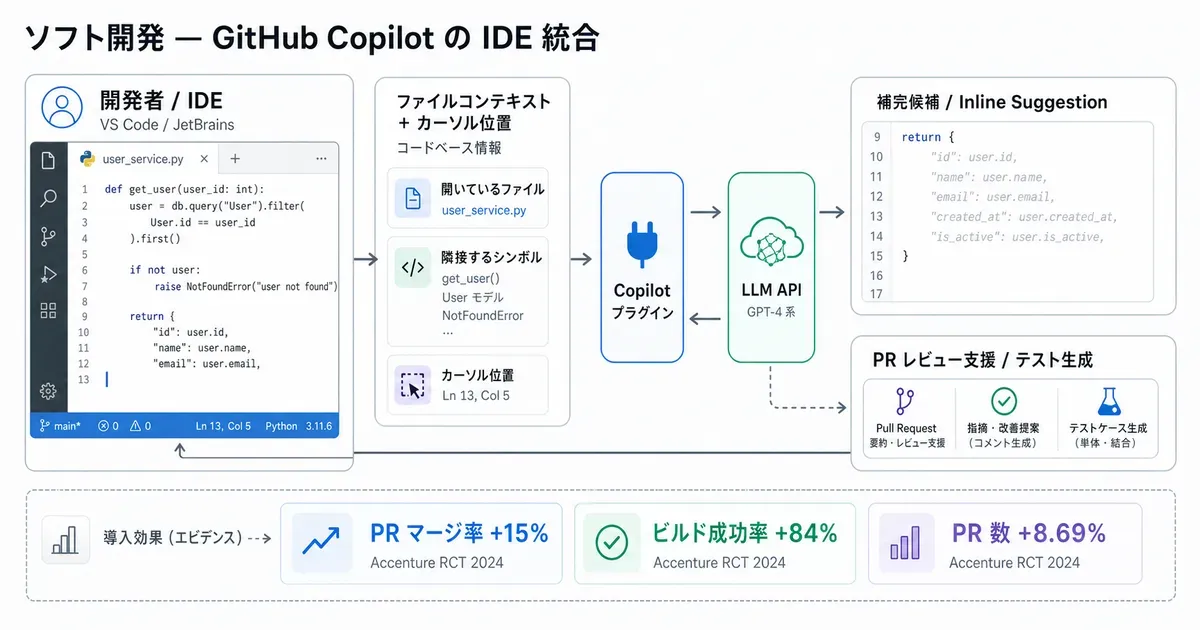
効果指標(GitHub Blog 2024-05-13 RCT):
- PR 数 +8.69% / PR マージ率 +15% / ビルド成功率 +84%
- 67% が週 5 日以上利用、90% が充実感、95% がコーディングを楽しく感じる
注意点: 「速度」と「質」を 同時に測った ところに価値があります。生産性 AI の効果評価は「コード行数」「タスク完了時間」など単一指標では危険で、マージ率・ビルド成功率まで含めて見ないとレビュー差し戻しの増加を見落とします。
6. カスタマーサポート — Klarna の AI チャット
事例: Klarna(スウェーデン本社のフィンテック)+ OpenAI 業務: 顧客問い合わせ応対(35 言語対応)、人間エージェントへのエスカレーション 採用技術: LLM チャット + 言語判定 + ナレッジ統合 + ハンドオフフロー
Klarna は 2024 年 2 月の発表で、AI チャットアシスタントが導入 1 か月で 月 230 万会話 を処理し、これは 700 FTE 相当 の業務量に相当すると述べました。解決時間は 11 分から 2 分 に短縮、再問合せ率は -25%、年間 4,000 万ドル の利益貢献が見込まれるとされています。
ところが Klarna は 2025 年に AI 集中投資の方針を見直し、人間エージェントの 部分的な再雇用 に踏み切ったと報じられました。背景には、品質低下と顧客体験の劣化、特に複雑な問い合わせでの満足度低下があったとされます。これは「数字上の効率」と「体験の質」が別軸であることを最も鮮明に示す事例です。
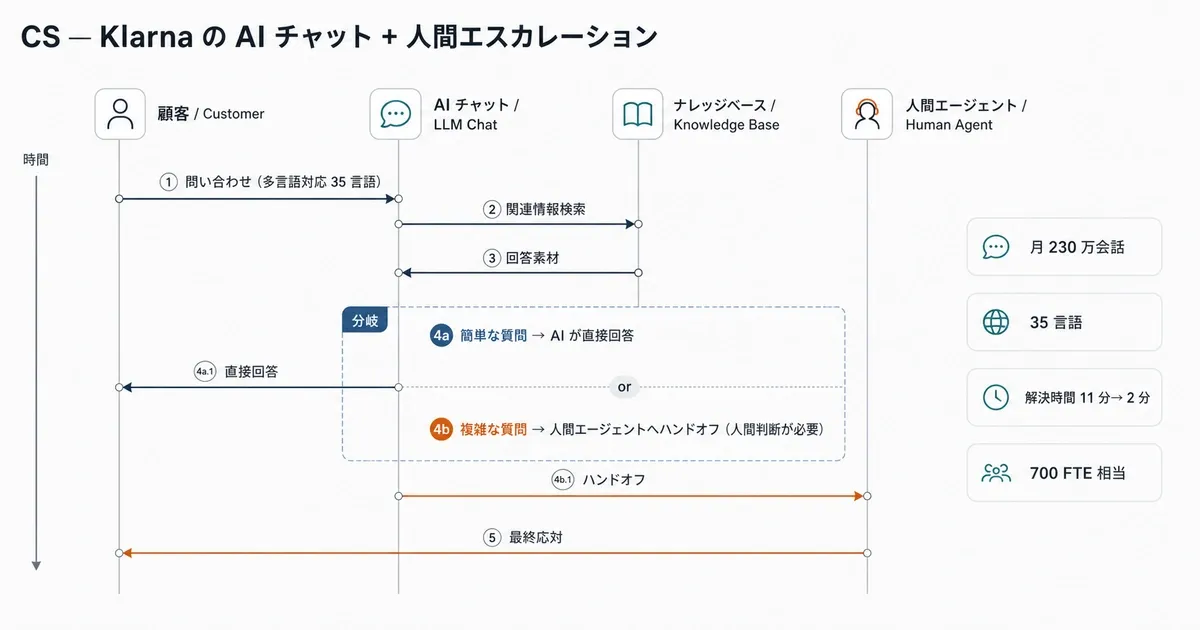
効果指標(2024 年発表時点):
- 月 230 万会話 / 700 FTE 相当 の業務代替
- 解決時間 11 分 → 2 分、再問合せ -25%、利益貢献 約 $40M
比較・代替手法
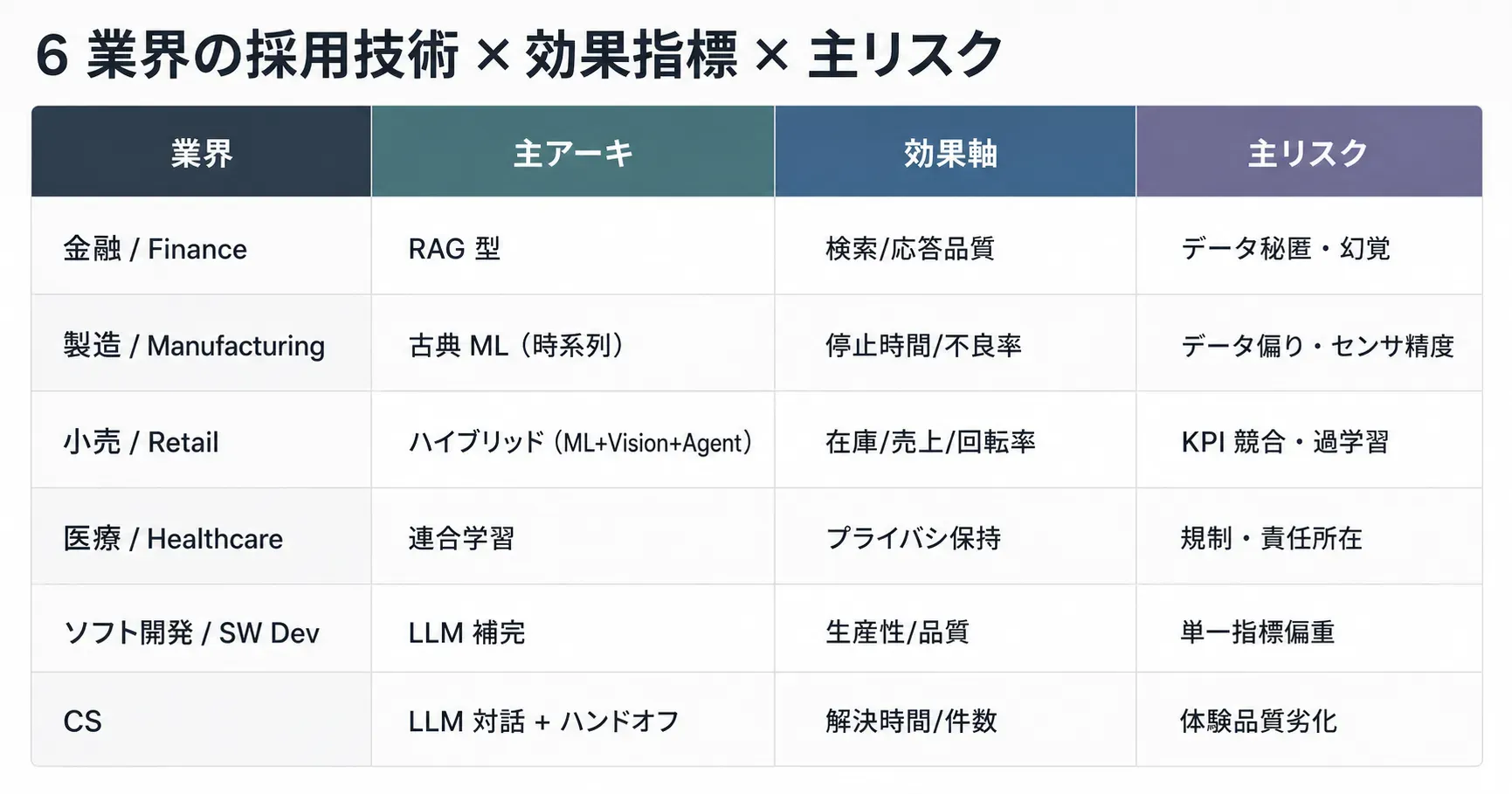
6 業界の事例を 採用アーキ・効果軸・主リスク の観点で並べると、共通項とトレードオフが見えてきます。自社業務に当てはめる際は、似たアーキを取った業界のリスクを先に潰しておくと PoC が空回りしません。
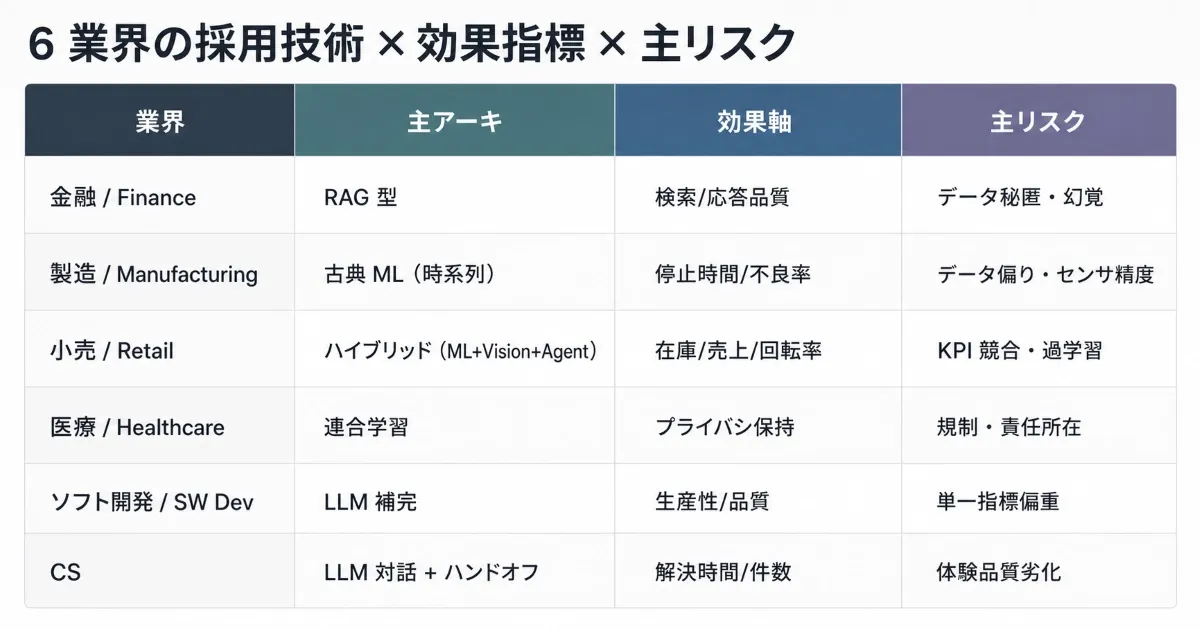
| 業界 | 主アーキ | 効果軸 | 主リスク |
|---|---|---|---|
| 金融 | RAG 型 | 検索 / 応答品質 | データ秘匿・ハルシネーション |
| 製造 | 古典 ML(時系列) | 停止時間 / 不良率 | データ偏り・センサ精度 |
| 小売 | ハイブリッド(ML + Vision + Agent) | 在庫 / 売上 / 回転率 | KPI 競合・過学習 |
| 医療 | 連合学習 | プライバシ保持 | 規制・責任所在 |
| ソフト開発 | LLM 補完 | 生産性 / 品質 | 単一指標偏重 |
| CS | LLM 対話 + ハンドオフ | 解決時間 / 件数 | 体験品質劣化 |
事例横断で抽出される AI に向く業務 / 向かない業務 を、6 業界の経験から再分類すると次のようになります。前回記事の整理よりも「実運用で出てきた境界線」に寄せています。
| 性質 | 向く業務 | 向かない業務 |
|---|---|---|
| 入力の構造 | 半構造ドキュメント検索(Morgan Stanley)、自然言語応対(Klarna) | 物理計測の最終判断(医療画像の確定診断) |
| 判断責任 | 補助的判断(Copilot の補完候補) | 法的・医療的最終責任を伴う判断 |
| データ偏在 | センサー時系列が既に十分(BMW) | 異常データが極端に少ない希少事象 |
| 効果計測 | 速度 + 品質を両側測れる(PR マージ率 + ビルド成功率) | 単一指標しか測れない領域(数字盲信に陥りやすい) |
私の考察
私が 6 業界を並べてみて最も強く感じたのは、「アーキタイプは 3 つに集約される」 ということです。1 つ目は RAG 型(金融・CS・ソフト開発の一部)で、社内ナレッジを LLM に補完させて応答品質を引き上げる構成です。2 つ目は Vision / 古典 ML 型(製造・小売の一部)で、画像認識や時系列予測といった LLM 以前からの ML を主役に据えます。3 つ目は ハイブリッド型(小売・医療)で、複数のモデルとエージェント層を束ねて多重最適化や規制対応を実現します。自社業務をどのアーキタイプに当てはめるか を最初に決めると、技術選定とベンダー選びが一気に具体化します。
次に強く感じたのは、Klarna 事例から学ぶ「数字盲信のリスク」 です。「700 FTE 相当」「$40M」「解決時間 -82%」は強烈な数字ですが、品質劣化と方針転換まで含めて見ると単純な成功談にはなりません。私が業務で AI 導入を進める立場であれば、効率指標(時間・コスト)と体験指標(満足度・解約率)を別軸で同時に測る ダッシュボードを最初に組みます。導入後 3-6 か月で体験指標が悪化していないかをモニタする運用を、リリース計画の中に最初から書き込んでおくのが安全です。
最後に、6 業界に共通する成功要因として 「何をやらないか」の境界線設定 を挙げたいと思います。Mayo Clinic は最終診断責任を AI に移していません。Morgan Stanley は最終的な顧客対応をアドバイザに残しています。BMW は故障判断ではなく「兆候検知」に範囲を絞っています。「何をやるか」より「何をやらないか」を最初に明確化すること が、結局のところ導入の成否を決めると私は考えます。AI が万能になるほど、「人間判断を残す境界線」を意識的に設計することが重要になっていきます。
参考リンク
- Morgan Stanley uses AI evals to shape the future of financial services — OpenAI 公式事例
- Key Milestone in Innovation Journey with OpenAI — Morgan Stanley Press
- Smart maintenance using artificial intelligence — BMW Press, 2023-11-27
- Artificial Intelligence at BMW — Emerj
- Walmart’s AI-powered inventory system brightens the holidays — Walmart Global Tech Blog
- Amazon and Walmart are setting the retail industry’s AI agenda — SymphonyAI(業界レポート)
- Mayo Clinic accelerates personalized medicine through foundation models — Mayo Clinic News Network
- Mayo Clinic - Google Cloud Partnership Case Study — NCBI / NIH
- Research: Quantifying GitHub Copilot’s impact in the enterprise with Accenture — GitHub Blog, 2024-05-13
- How Accenture uses GitHub — GitHub Customer Stories
- Klarna AI assistant handles two-thirds of customer service chats in its first month — Klarna Press
- Klarna’s AI assistant — OpenAI 公式事例
関連する記事
AIを競争優位の堀に変える企業ユースケース
AI モデルのコモディティ化を前提に、データフライホイール・ネットワーク効果・組織コンテキスト・統合・独占資産という5つの“堀”の型ごとに、Tesla・Amazon・TikTok・Stripe 等の具体例で「なぜ競合が真似できないか」を整理し、自社の競争優位の作り方を考えます。

業務で言われる『AI』の実態 — LLM・RAG・エージェントの動作を図で理解
業務サイドが日々耳にする『AI 利活用』の中身を、LLM の入出力・RAG の知識補完・エージェントのツール実行という3つの構成要素に分解し、図とともに解説します。コールセンター・社内検索など複数業種の具体例を示し、過信せず使うための観点を整理します。
RAG vs ファインチューニング — どちらをいつ選ぶか
LLM に独自知識を持たせる代表的な 2 つのアプローチ、RAG(検索拡張生成)とファインチューニングを 7 軸で比較し、実務での判断フローとハイブリッド戦略を整理します。