

LLM のコンテキストウィンドウとは何か — トークン制約と 1M 時代の判断軸
LLM が一度に処理できる『記憶の窓』であるコンテキストウィンドウについて、トークンの定義・入出力共有予算の実態・2026 年時点の主要モデル比較を整理します。1M トークン時代の選び方と落とし穴を、業務サイドにも分かる粒度で図解します。
TL;DR
- コンテキストウィンドウ = LLM の working memory: 一度に処理できるトークンの上限。プロンプト・履歴・出力すべてがこの枠を共有します。
- トークン: 文字よりも粗い単位で、1,000 トークン ≒ 日本語 700 字 / 英語 750 単語が目安。tokenizer により変動します。
- 入出力で同じ予算を消費: 128K の窓を持つモデルに 100K の入力を渡すと、出力に使えるのは残り 28K のみ。「窓に入れる量」と「答えの長さ」がトレードオフです。
- 2026 年は 1M トークンが標準級: Claude Opus 4.7 / GPT-5.5 / Gemini 1.5 Pro が 1M に対応、Llama 4 Scout は 10M。
- 大きい = 良い ではない: 注意散漫 (lost in the middle)・推論コスト増・課金上昇など、長コンテキストには明確な代償があります。
要点サマリ表
| 観点 | 内容 |
|---|---|
| 何の話 | LLM が「どれだけ覚えていられるか」を決める仕様の解説 |
| 定義 | 一度に処理可能なトークン数の上限 (入出力含む共有予算) |
| 影響範囲 | 長文要約・RAG の Top-K 設計・エージェントの履歴設計・API コスト全般 |
| 2026 年の標準 | 主要モデルは 1M、極端な例で 10M (Llama 4 Scout) |
| 私の評価 | 数字に踊らされず「使う分だけ渡す」運用が定番。1M = 何でも投げ込め、ではない |
背景・経緯
LLM のコンテキストウィンドウは、ここ数年で 桁違いの拡張 を遂げてきました。2022 年末に公開された ChatGPT 初期は 4K トークン(約 3,000 日本語字)が上限で、長文を渡すと前半が打ち切られるのが日常でした。
2024 年前後で 128K が一般化し、PDF 1 冊や数時間の議事録をまとめて渡せる規模になりました。さらに 2025 年〜2026 年にかけて 1M トークン が複数モデルで標準化し、書籍数冊や数十万行のコードベースを一気に扱う運用が現実的になっています。
数字だけ見ると順調な拡張ですが、業務サイドで実際に触ってみると 「広ければ広いほど良い」とは限らない ことが分かります。情報を多く詰め込むほど推論精度が落ちる「lost in the middle」現象や、推論コストの跳ね上がりなど、見えにくいトレードオフが背後に常にあります。
本記事ではコンテキストウィンドウの 定義・実態・2026 年スナップショット・落とし穴 を順に整理し、業務サイドが意思決定で迷わないための判断軸をまとめます。
本題の詳細
コンテキストウィンドウの定義 — LLM の”記憶の窓”
コンテキストウィンドウ (context window) は、LLM が 一度のリクエストで考慮できるトークン総量の上限 です。IBM の定義では「単一のリクエスト・レスポンスサイクルで処理可能なトークン総数」、Anthropic の API ドキュメントでも同義に扱われています。
重要なのは、ウィンドウが 「入力 + 出力」を含む合算予算 だという点です。会話 UI で履歴が積み上がってもこの枠から差し引かれ、システムプロンプトやツール定義もすべて同じ予算を消費します。
技術的には Transformer 系 LLM の自己注意機構 (self-attention) がこの上限を決めています。各トークンが他のすべてのトークンに「注意」を向ける計算は、シーケンス長の二乗で増えるため、コンテキストを倍にするとアテンション層の計算量はおおよそ 4 倍になります。これが長コンテキスト対応のコストが跳ね上がる根本理由です。
トークンとは何か — 文字よりも粗い単位
LLM は文字を直接処理しているわけではなく、トークン (token) という文字よりも粗い単位に分解してから扱います。モデルごとに tokenizer という分割ルールがあり、英語なら単語より少し細かい単位、日本語なら文字より少し粗い単位、というのが平均的な姿です。
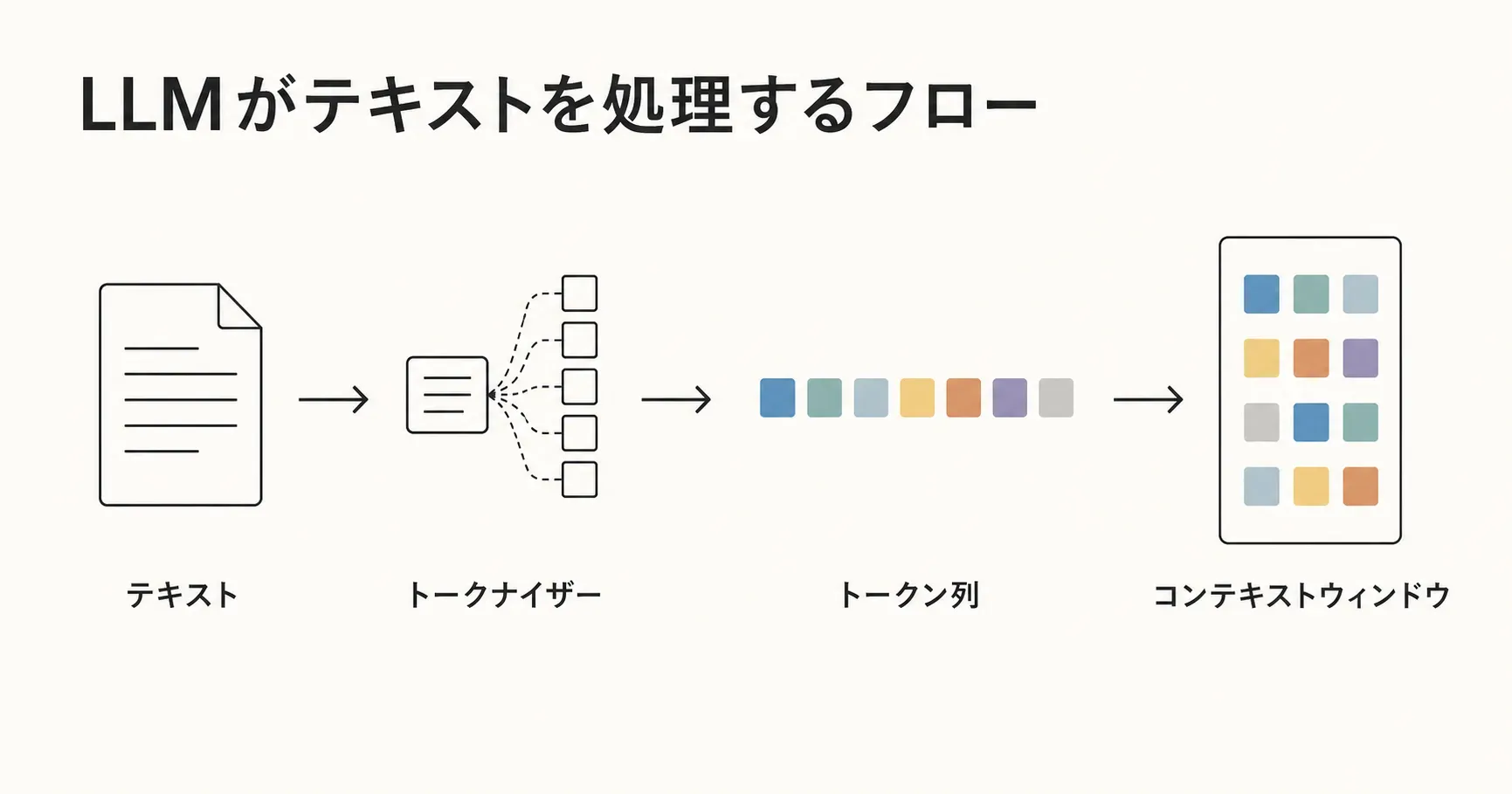
ざっくりした目安として、1,000 トークン ≒ 日本語 700 字 / 英語 750 単語 が業界一般の換算です。日本語は分かち書きがないため英語より tokenizer 効率が悪く、同じ意味内容を伝えるのにトークンを多めに消費する傾向があります。
業務サイドが押さえておくと役立つのは次の 3 点です:
- プロンプト + 出力の合計 がコンテキストウィンドウから引かれる (後述 5-3 で詳細)
- API 課金は基本的にトークン単位 (Claude Sonnet で 100 万トークンあたり数ドル規模)
- モデル間で tokenizer が違う ため、同じ文章でもトークン数が変わる
共有予算の実態 — プロンプトも出力も同じ枠を取る
コンテキストウィンドウを 「予算」 として捉えると、その内訳は次の 4 つに分かれます。

業務利用で陥りがちな誤解は、「入力さえ収まれば大丈夫」 という思い込みです。実際には出力もこの予算から差し引かれるため、128K のモデルに 120K の入力を投げると 出力に使える残り 8K で要約せざるを得ない という事態になります。
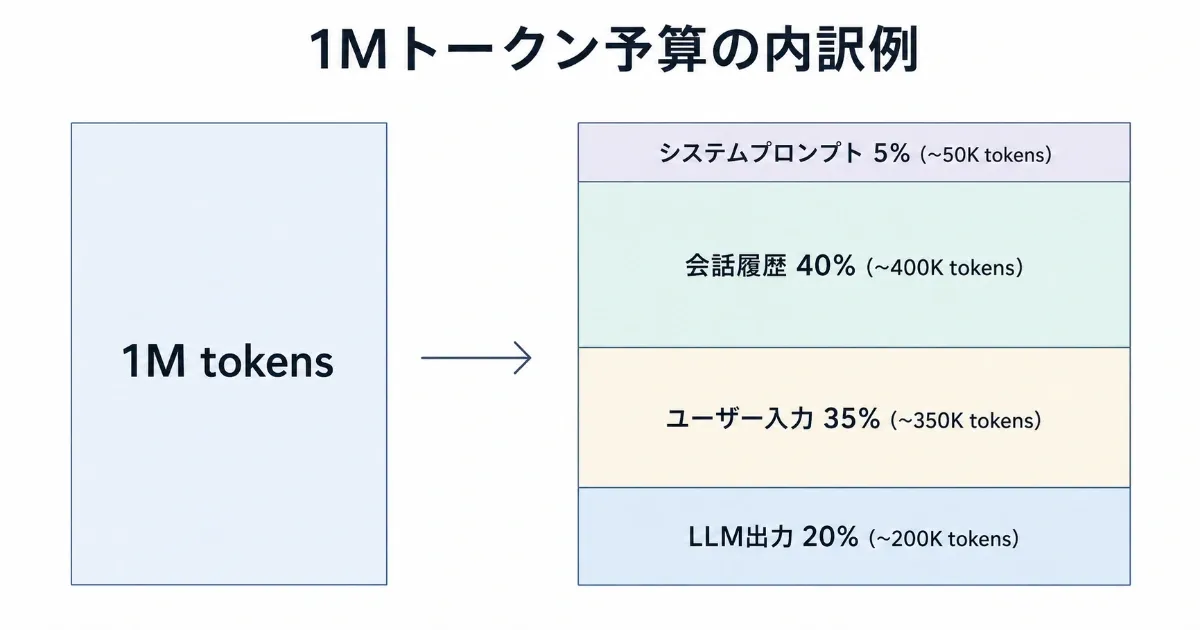
実務的な分配の感覚として、私は次のように予算を割っています:
- System プロンプト: 全体の 5-10% (役割・口調・禁止事項)
- History (会話履歴): 30-50% (直近のターン 10-20 回程度)
- User Input: 30-40% (RAG なら検索結果込み)
- Output: 10-20% (回答長として確保)
この比率は記事執筆・コード生成・チャット応答など用途で変わりますが、「出力分を最初から確保しておく」 という発想は共通です。
2026 年スナップショット — 主要モデルの状況
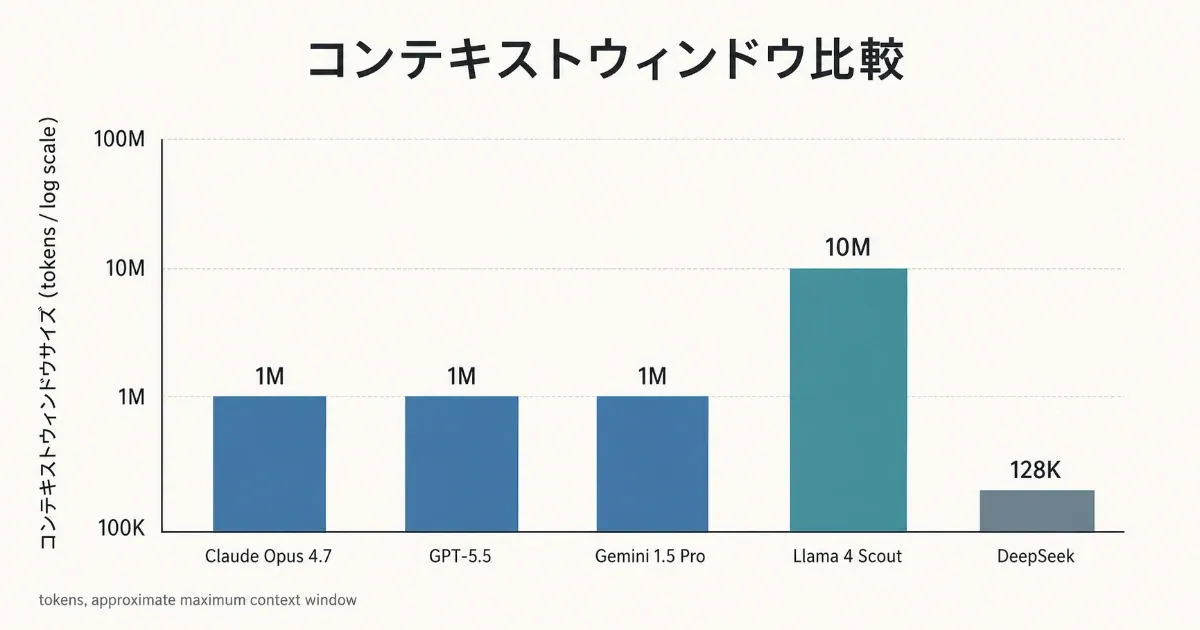
2026 年 5 月時点での主要モデルのコンテキストウィンドウは次の通りです (出典: Anthropic Docs / Karo Zieminski Substack / Framia)。
| モデル | コンテキスト窓 | 価格モデル | 備考 |
|---|---|---|---|
| Claude Opus 4.7 | 1M | フラット課金 (長くても単価不変) | 2026-03-13 に 1M GA |
| Claude Sonnet 4.6 | 1M | フラット課金 | 同上 |
| GPT-5.5 | 1M (API) / 400K (Codex) | 272K 超で入力単価 2 倍 | 2026-04-23 リリース |
| Gemini 1.5 Pro | 1M | 階層課金 | Gemini 1.5 Flash は 2M |
| Llama 4 Scout | 10M | OSS (自社運用次第) | 2026 年現在の最大級 |
| DeepSeek / Mistral | 128K | 安価 | コスト重視の選択肢 |
注目すべきは 価格モデルの違い です。Claude は 1M トークン全域で単価が変わりませんが、GPT-5.5 は 272K を超えると入力単価が 2 倍に跳ね上がります (Framia 報告)。長文を頻繁に扱うワークロードでは、ウィンドウサイズの数字だけでなく 「フラットか段階的か」 が稟議で重要な判断軸になります。
比較・代替手法
「窓を広げる」以外にも、コンテキスト不足を回避する手段はあります。実務では複数を組み合わせるのが現実的です。
| 手段 | 仕組み | 向く場面 | 弱点 |
|---|---|---|---|
| 窓を大きいモデルに替える | 128K → 1M モデルへ | 一度に大量資料を渡したい | コスト増、lost in the middle |
| RAG (検索拡張生成) | 検索で関連箇所だけ渡す | 知識量が膨大、出典追跡が必要 | 検索品質に依存、構築コスト |
| 要約 + 階層化 | 過去履歴を要約してから渡す | 長期会話、エージェント | 要約時の情報欠落 |
| プロンプト最適化 | 冗長な指示を圧縮 | コスト最優先 | 情報量とのトレードオフ |
| キャッシング | 共通プロンプトを再利用 | 同一プロンプト多発 | 設計コスト |
「とりあえず 1M」と飛びつく前に、まず どこに無駄な消費があるか を分析するのが先決です。多くのケースで RAG + プロンプト最適化の組み合わせのほうが、純粋な窓拡張より費用対効果が高くなります。
私の考察
私が業務サイドに伝えたいのは、「コンテキストウィンドウは大きさで選ぶものではない」 という点です。1M に対応したから安心ではなく、むしろ 「使い方を設計する」 ことが本質的な仕事になります。
第一に、lost in the middle を前提に設計する ことです。1M を埋め尽くす運用は技術的に可能でも、実務上は精度が落ちます。重要情報は冒頭か末尾に置く、長文は要約してから渡す、というプロンプト設計の習熟がコスト削減と精度向上の両方に効きます。
第二に、価格モデルの差を稟議に反映する ことです。GPT-5.5 の段階課金は、272K を頻繁に超えるワークロードでは単価が実質倍になります。月額試算では「平均トークン数」だけでなく「分布」を見て、長文比率が高ければ Claude のフラット課金が有利、というケースが頻繁に起きます。
第三に、RAG + 適切なウィンドウ の組み合わせを基本姿勢にすることです。すべてを 1M に詰め込むより、「検索で絞ってから 128K-256K で処理する」ほうが、コスト・精度・運用負荷の三拍子で勝ることが多いです。Cloudflare Workers AI のような軽量モデルでも、RAG と組み合わせれば実用的な品質に到達します。
最後に強調しておきたいのは、この比較は永久に同じ結論ではない という点です。Llama 4 Scout の 10M、将来の 100M クラスが標準化したとき、現在の判断軸は再構成が必要になります。今 (2026 年 5 月) の私の判断は「1M モデルをデフォルトに、必要分だけ渡す運用」ですが、半年後にこの記事を読み返したときに自分の判断がアップデートされている可能性は十分ありえます。
参考リンク
- What is a context window? — IBM Think
- Context windows — Claude API Docs — Anthropic 公式
- Context window — Wikipedia
- Claude’s 1 Million Context Window: What Changed and When It’s Worth Using (2026) — Karo Zieminski
- GPT-5.5 Context Window: The 1 Million Token Advantage — Framia
- Token Optimization and Cost Management for ChatGPT & Claude — IntuitionLabs
関連する記事

業務で言われる『AI』の実態 — LLM・RAG・エージェントの動作を図で理解
業務サイドが日々耳にする『AI 利活用』の中身を、LLM の入出力・RAG の知識補完・エージェントのツール実行という3つの構成要素に分解し、図とともに解説します。コールセンター・社内検索など複数業種の具体例を示し、過信せず使うための観点を整理します。
生成AI開発のセキュリティ:どこで何を守るか
生成AIを使った開発(Claude CodeやCursor等)でどこに何のセキュリティリスクが潜むかを、データフロー図で整理しました。プロンプトインジェクションや企業秘密の漏洩を、入力・出力・権限・量の4観点で多層に防ぐ設計をOWASP LLM Top 10とAWS IAM条件キーを交えて解説します。
RAG vs ファインチューニング — どちらをいつ選ぶか
LLM に独自知識を持たせる代表的な 2 つのアプローチ、RAG(検索拡張生成)とファインチューニングを 7 軸で比較し、実務での判断フローとハイブリッド戦略を整理します。