
生成AI開発のセキュリティ:どこで何を守るか
生成AIを使った開発(Claude CodeやCursor等)でどこに何のセキュリティリスクが潜むかを、データフロー図で整理しました。プロンプトインジェクションや企業秘密の漏洩を、入力・出力・権限・量の4観点で多層に防ぐ設計をOWASP LLM Top 10とAWS IAM条件キーを交えて解説します。
TL;DR
- データフローで考える: 生成AI開発のリスクは「入力 → 推論 → 実行 → 認証情報 → 出口 → クラウド」のどこにでも潜みます。まずどこに境界があるかを把握することが出発点です。
- モデルの判断を信用しない: プロンプトインジェクションや確率的脆弱性により、モデルへの指示は確実には守られません。安全性は確定的な仕組みで担保すべきだと私は考えます。
- 企業秘密の漏洩は3経路: 機密の漏洩は「入力経路」「出力経路」「境界経路」に分かれます。OWASP の LLM02:2025 Sensitive Information Disclosure に対応します。
- 多層防御の4観点: 「入力を絞る」「出力を絞る」「権限を絞る」「量を絞る」を独立した層として重ね、ある層が破られても別層で防ぐ設計が現実解です。
- 人手の逐次確認は限界: 規模が拡大すると承認疲れで判断が劣化します。裁量を与えつつ仕組みで守る方向への移行が必要だと考えます。
要点サマリ
| 項目 | 内容 |
|---|---|
| 何の話 | 生成AIを使った開発で、どこに何のセキュリティリスクがあり、どう守るか |
| 結論 | モデルの判断を信用せず、データフローの各境界を確定的な仕組みで多層に守る |
| 影響範囲 | AIコーディングエージェントを業務で使う全チーム。特に機密コードを扱う組織 |
| 私の評価 | 条件付き採用。多層防御を前提に組めば実用的、無防備な導入は危険 |
背景・経緯
ここ数年で AIコーディングエージェント(Claude Code / Cursor / Devin 等)が急速に普及しました。これらは単にコードを提案するだけでなく、ファイル編集・コマンド実行・外部 API 呼び出しまで自律的に行います。
エージェントに与える「裁量・権限・並列度」は年々拡大しています。人間が一手ずつ確認していた作業を、AI が並列で何十手も進める時代に入りました。便利さの裏で、攻撃面(アタックサーフェス)も同じだけ広がっています。
従来の安全策は、人間が AI の各操作を逐次確認する「方向性A」でした。今のところは機能しますが、規模が拡大すると承認疲れにより判断が雑になり、結局は中身を見ずに承認してしまう劣化が起きます。
そこで注目されているのが、AI に十分な裁量を与えつつ、危険な操作は仕組みで確定的に止める「方向性B」です。本記事では、クラスメソッド DevelopersIO の整理を土台に、データフローのどこで何を守るべきかを図とともに整理します。
本題の詳細
リスクはデータフローのどこに潜むか
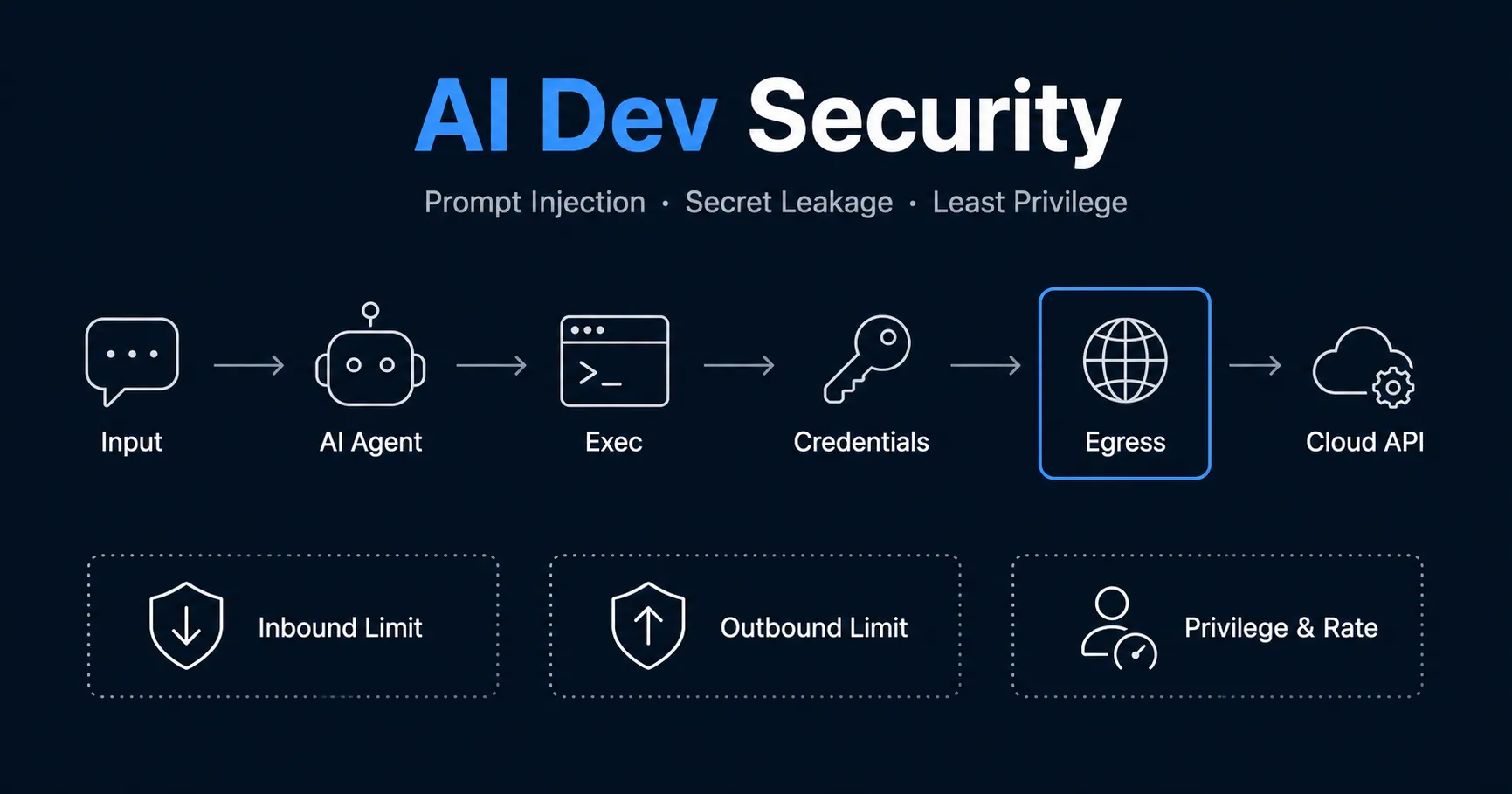
まず、生成AI開発のデータの流れと信頼境界を図にしました。リスクは特定の一点ではなく、流れの各境界に分散して存在します。
flowchart LR subgraph trusted["ローカル・信頼境界内"] direction LR IN["入力ソース<br/>コード・ドキュメント・Web<br/>守る点: プロンプトインジェクション対策/機密を入力に含めない"] LLM["AIエージェント・LLM推論<br/>守る点: モデルの判断を信用しない"] EXEC["ローカル実行環境<br/>CLI・ファイル操作<br/>守る点: 最小権限・Sandbox"] CRED["認証情報<br/>~/.aws・APIキー・環境変数<br/>守る点: 差し替え・窃取防止"] end subgraph external["外部・境界の外"] direction LR EGRESS["ネットワーク出口・egress<br/>守る点: egress制限/ドメイン+量制限/機密の外部流出防止"] CLOUD["クラウドAPI・外部リソース<br/>守る点: IAM条件キーでクロスアカウント拒否"] end IN --> LLM --> EXEC --> CRED --> EGRESS --> CLOUD
入力ソースは、コード・社内ドキュメント・Web 上の情報など、AI が読み込むすべてです。ここに攻撃者の仕込んだ指示が混入すると、後段すべてが汚染されます。機密を不用意に含めないことも重要です。
**AIエージェント(LLM推論)**は、入力を解釈して次の行動を決める頭脳です。ここでの大原則は「モデルの判断を信用しない」ことだと私は考えます。指示通りに動く保証がないためです。
ローカル実行環境は、AI が実際にコマンドやファイル操作を行う場です。最小権限と Sandbox(隔離環境)で、できることの範囲を狭めます。
認証情報(~/.aws の資格情報・API キー・環境変数)は、攻撃の最終目的になりやすい資産です。差し替えや窃取を防ぐ必要があります。**ネットワーク出口(egress)**は機密が外部へ出ていく最後の関所で、クラウドAPI・外部リソースは流出先になり得ます。
主要リスクの全体像
データフローの各境界に紐づく主要リスクを、7 つに整理します。多くは OWASP Top 10 for LLM Applications 2025 に対応します。
- プロンプトインジェクション(OWASP LLM01): 入力に紛れた悪意ある指示で AI を乗っ取る攻撃。2025 版でも 1 位に位置づけられています。
- データポイズニング(OWASP LLM04 Data and Model Poisoning): 学習データや参照データに汚染を仕込み、モデルの振る舞いを歪める攻撃です。
- 確率的脆弱性: LLM は本質的に確率的で、
temperature=0でも完全な決定論にはなりません (要検証)。システムプロンプトの制約も確率的に突破され得ます。 - 認証情報の差し替え: AI を誘導し、正規の認証情報を攻撃者の管理するものへ置き換えさせる攻撃です。
- クロスアカウント漏洩: 許可ドメイン内に攻撃者のアカウントがあると、通信先としては正常に見えるため検知が困難です。
- 操作反復による暴走: 同じ操作を延々と繰り返し、コストや可用性を破壊するリスクです。量と回数の制御が要点になります。
- 並列実行の積み重ね: 各層の確率的脆弱性が並列実行で積み重なり、どこかで確実に破られる確率が上がります。
企業秘密・機密データの漏洩リスク
ユーザーから特に厚く扱ってほしいと依頼があったのが、この企業秘密・機密データの漏洩です。OWASP の LLM02:2025 Sensitive Information Disclosure に対応する領域で、生成AI開発で最も実害が出やすいリスクの一つだと私は考えます。
漏洩は発生する場所によって、次の 3 経路に分けると整理しやすくなります。
入力経路の漏洩は、機密ソースコード・API キー・顧客データ・社外秘ドキュメントを、プロンプトやコンテキストに含めて外部 LLM プロバイダへ送信してしまうケースです。送信した情報が学習データに取り込まれたり、ログとして保持されたり、第三者に露出したりするリスクがあります。
出力経路の漏洩は、モデルが学習データ由来の機密(例: 本番の認証情報)を出力に漏らすケースです。意図せず他者の秘密がアウトプットに混じる可能性があります。
境界経路の漏洩は、egress やクロスアカウント経由で機密が外部リソースへ流出するケースです。前節「リスクはデータフローのどこに潜むか」「主要リスクの全体像」で触れた境界の問題と地続きになっています。
対策は経路ごとに重ねます。入力側では「機密を送らない」を原則に、マスキングやデータサニタイズを行います。契約面では学習不使用 + ゼロ保持のエンタープライズ契約、あるいは self-host(自社環境での実行)を選びます。出力側では出力監視を、境界側では最小権限・egress 制限・DLP(データ漏洩防止)を組み合わせます。
多層防御の設計 ― 4観点
ここまでのリスクを踏まえると、守り方は「入力・出力・権限・量」の 4 観点に集約できます。基本原則は 2 つです。第一に「モデルの判断を信用しない」こと、つまり確定的な仕組みで制御すること。第二に「独立した複数層を重ね、ある層が破られても別層で防ぐ」ことです。
単独の対策には、それぞれ限界があります。次の表に、よくある対策と単独運用時の弱点を整理しました。
| 対策 | 単独での限界 |
|---|---|
| 人手で全承認 | × 承認疲れで判断が劣化する |
| AIによるコマンド安全性チェック | × 実環境で見逃し率(FNR)17% |
| ブラックリスト | × 迂回路が無数にあり塞ぎきれない |
| ホワイトリストのみ | × 任せる範囲を狭く固定するしかない |
| ドメイン制限のみ | × 許可ドメイン内の攻撃者は検知不可 |
| 権限種別のみ | × 量・回数の暴走を防げない |
つまり、どれか一つに頼るのではなく、4 観点を独立した層として重ねることが要点になります。具体的な実装機構は次の通りです。
- ①入力範囲を絞る: AI に渡す情報を限定し、機密や不審な入力を排除します。
- ②出力(送り出せる)範囲を絞る: AI が外部へ送れる宛先・内容を制限します(egress 制限)。
- ③実行可能な作業・権限を絞る: 最小権限を徹底します。Claude Code の permissions(allow / deny / ask)・権限モード・Sandbox・hooks(
PreToolUse/PostToolUse)でツール実行を制御できます。クラウド側では AWS IAM 条件キーaws:ResourceOrgID/aws:ResourceAccountでクロスアカウントを既定拒否し、VPC エンドポイントポリシーやセキュリティグループで通信を絞ります。 - ④回数・量を絞る: レート上限・量上限を設け、操作反復による暴走を止めます。
これらの設計全体は NIST Cybersecurity Framework(特定 / 防御 / 検知 / 対応 / 復旧 / ガバナンス)の枠組みにも対応づけられます。最後に、4 観点のガードを図にまとめます。
flowchart TB REQ["AIエージェントの要求"] L1["第1層: 入力範囲を絞る<br/>機密・不審入力を排除"] L2["第2層: 出力範囲を絞る<br/>egress制限・送信先限定"] L3["第3層: 権限を絞る<br/>最小権限・Sandbox・IAM条件キー"] L4["第4層: 量を絞る<br/>レート上限・回数上限"] OK["許可された安全な操作"] REQ --> L1 --> L2 --> L3 --> L4 --> OK
比較・代替手法
冒頭で触れた「方向性A(人手で逐次確認)」と「方向性B(裁量+仕組みで担保)」を、観点別に比較します。
| 観点 | 方向性A:人手で逐次確認 | 方向性B:裁量+仕組みで担保 |
|---|---|---|
| 拡張性 | × 低い。人の確認がボトルネック | ○ 高い。仕組みが自動で制御 |
| スピード | × 遅い。逐次承認が必要 | ○ 速い。安全範囲は自走 |
| 安全性の担保方法 | △ 人の注意力に依存 | ○ 確定的な多層の仕組み |
| 規模拡大時 | × 承認疲れで判断が劣化 | ○ 層を足して対応可能 |
| 向くケース | 小規模・短期・試験運用 | 業務での継続運用・並列実行 |
方向性A が常に劣るわけではなく、小規模や短期の試行では十分機能します。ただし規模拡大を見据えるなら、方向性B への移行を前提に設計すべきだと私は考えます。
私の考察
私がこのテーマで重視している判断軸は 2 つです。第一に「モデルの判断を信用せず、確定的な仕組みで多層に守る」こと。第二に「機密は境界の外に出さない設計を既定にする」ことです。
LLM は確率的に動くため、「指示すれば守ってくれる」前提は危ういと考えます。実環境での見逃し率が 17% という数字(DevelopersIO 出典)は、AI による安全性チェックを唯一の砦にできないことを示しています。だからこそ、入力・出力・権限・量の独立した層を重ね、どこか一層が破られても別の層で止める設計が現実解になります。
機密データについても、「漏れたら困るもの」を最初から境界の外に出さない設計を既定にすべきです。マスキング・学習不使用契約・egress 制限・DLP を、後付けではなく初期設計に組み込むことを私は推奨します。
参考リンク
関連する記事

LLM のコンテキストウィンドウとは何か — トークン制約と 1M 時代の判断軸
LLM が一度に処理できる『記憶の窓』であるコンテキストウィンドウについて、トークンの定義・入出力共有予算の実態・2026 年時点の主要モデル比較を整理します。1M トークン時代の選び方と落とし穴を、業務サイドにも分かる粒度で図解します。

業務で言われる『AI』の実態 — LLM・RAG・エージェントの動作を図で理解
業務サイドが日々耳にする『AI 利活用』の中身を、LLM の入出力・RAG の知識補完・エージェントのツール実行という3つの構成要素に分解し、図とともに解説します。コールセンター・社内検索など複数業種の具体例を示し、過信せず使うための観点を整理します。
RAG vs ファインチューニング — どちらをいつ選ぶか
LLM に独自知識を持たせる代表的な 2 つのアプローチ、RAG(検索拡張生成)とファインチューニングを 7 軸で比較し、実務での判断フローとハイブリッド戦略を整理します。