
AIを競争優位の堀に変える企業ユースケース
AI モデルのコモディティ化を前提に、データフライホイール・ネットワーク効果・組織コンテキスト・統合・独占資産という5つの“堀”の型ごとに、Tesla・Amazon・TikTok・Stripe 等の具体例で「なぜ競合が真似できないか」を整理し、自社の競争優位の作り方を考えます。
TL;DR
- AI 活用それ自体は table stakes(参入条件):基盤モデルには誰もが同条件でアクセスできるため、「AI を使っていること」はもはや差別化要因になりません。
- 差がつくのは真似できない堀(moat):競合が模倣できない自社固有の資産に AI を載せて初めて、持続的な競争優位が生まれます。
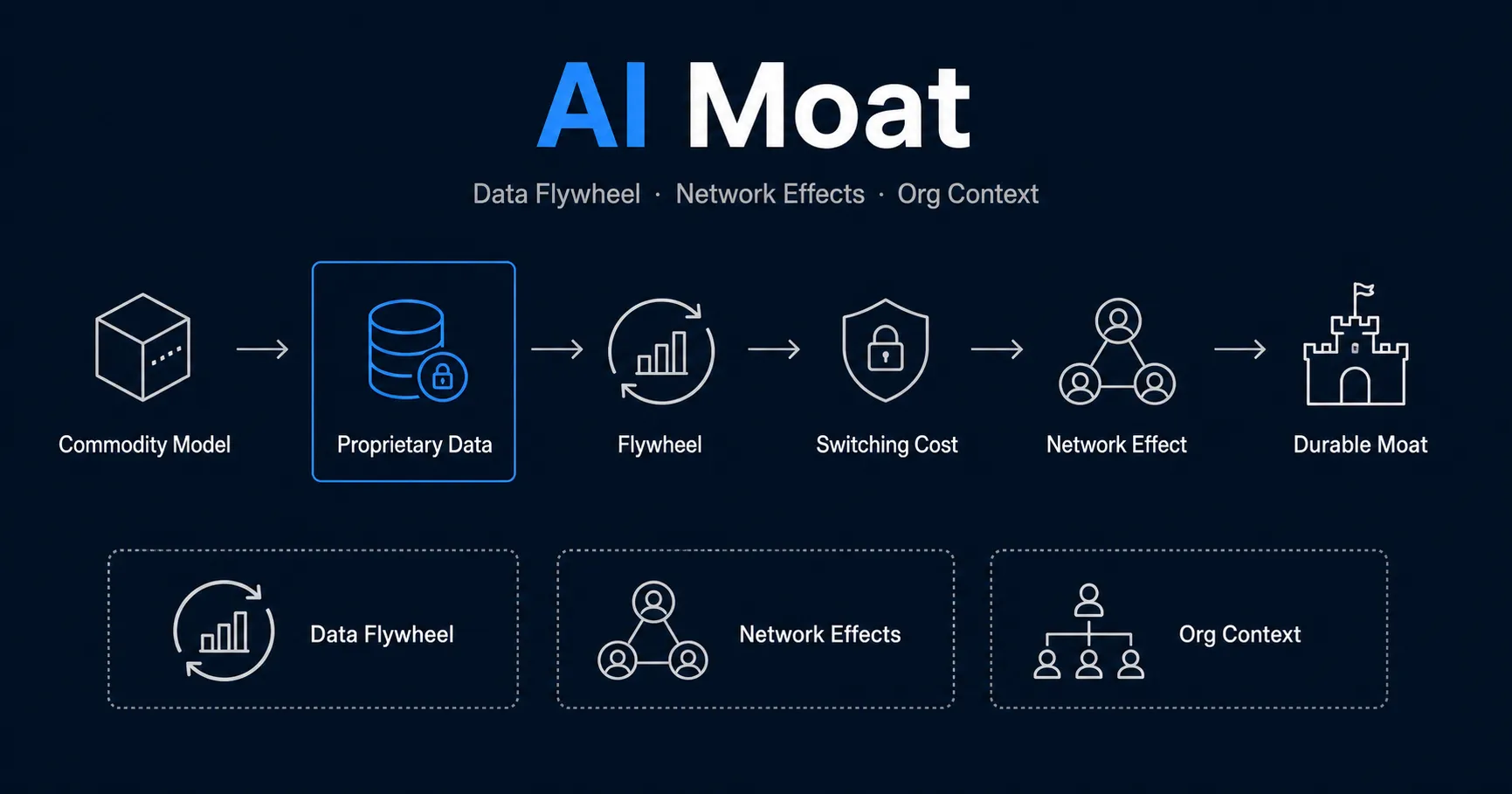
- 堀の型は大きく5つ:データフライホイール/ネットワーク効果/組織コンテキスト・実行知/統合とスイッチングコスト/独占・規制資産に整理できます。
- AI leader と laggard の格差は大きい:BCG の整理では、先行企業はコスト削減で約3倍、EBIT マージンで約1.6倍、ROIC で約2.7倍といった差が出ているとされます。
- 載せる土台が肝:AI は単独では堀になりません。自社固有データ・実行知・既存統合という土台に載せて、初めて競争優位へ転換します。
要点サマリ
| 何の話 | 結論 | 影響範囲 | 私の評価 |
|---|---|---|---|
| AI モデルのコモディティ化 | モデル利用自体は参入条件化(table stakes) | 全業界・全規模の企業 | 「AI 導入」をゴールにする経営判断は危険 |
| 競争優位の源泉 | 真似できない自社固有資産+AI の組合せ | 戦略・データ・組織設計 | ここに投資判断を集中させるべき |
| 堀の5類型 | データ・ネットワーク・コンテキスト・統合・独占 | 事業ポートフォリオ全体 | 自社がどの型を持てるかの見極めが要 |
| 先行と後発の格差 | コスト・利益・資本効率で顕著な差(BCG) | 中長期の競争地位 | 早期に「使うほど強くなる」構造を作る価値が高い |
背景・経緯
近年、基盤モデル(foundation model)の高性能化と API 提供の一般化により、ほぼすべての企業が同じレベルの AI 能力に同条件でアクセスできるようになりました。これは大きな解放であると同時に、「AI を使っていること」自体が差別化要因でなくなることを意味します。
McKinsey はこの状況を table stakes(参入条件)vs advantage(優位) という枠組みで整理しています。AI を本格的に活用する企業は EBIT マージンが他社より高い傾向にある(同社の整理では約20%高いとされます)一方で、その優位は AI ツールの導入そのものではなく、活用の深さに由来すると論じています。なお、この約20%という数字は「AI 採用企業 vs 非採用企業」を比較したものであり、後述する BCG の「先行企業(leader)vs 後発企業(laggard)」の比較とは、調査も比較対象も異なる独立した指標である点にご留意ください。
HBR は別の角度から同じ問題を指摘しています。誰もが同じモデル・同じツールを使える世界では、差別化の源泉は組織が持つコンテキスト(context)、すなわち固有の業務知識・データ・実行のしかたに移る、という主張です。モデルは共有財でも、それを意味あるアウトプットに変える文脈は共有できません。
BCG は、こちらは「先行企業 vs 後発企業」という別の切り口で格差の大きさを示しています。AI を先行活用する leader と後発の laggard の間には、コスト削減で約3倍、EBIT マージンで約1.6倍、ROIC で約2.7倍といった差が観測されるとされます (要検証)。これらは早期に「使うほど強くなる」構造を作ることの価値を示唆していると私は読みます。
本題の詳細
ここからは、競合が真似しにくい「堀」を5つの型に分け、それぞれ「何をしているか」と「なぜ競合が真似できないか」の2軸で具体例を見ていきます。
データフライホイール
データフライホイール(data flywheel) とは、利用が独自データを生み、そのデータがモデルや体験を改善し、改善がさらに利用を呼ぶ、という自己強化ループです。一度回り始めると、後発が同じ速度で追いつくことが構造的に難しくなります。
flowchart LR U["利用が増える<br/>ユーザー・取引・走行データ"] D["独自データが貯まる<br/>他社が持てないシグナル"] M["モデルと体験が改善<br/>精度・推薦・予測が向上"] V["差別化が増す<br/>乗り換えしにくくなる"] U --> D --> M --> V --> U
何をしているか:Tesla は販売した車両の走行データを継続的に収集し、自社の学習基盤(Dojo と呼ばれる学習インフラ)で運転支援モデルを訓練し、改善を OTA(Over The Air) で全車両に配信しています。配信された性能向上がさらに多様な走行データを生み、ループが回り続けます。Amazon も購買・閲覧・検索といった行動シグナルをレコメンド・需要予測・広告最適化に還元しており、その広告事業の売上は年間で約 $68B 規模に達したとされます (要検証)。
なぜ競合が真似できないか:後発企業は、同等のセンサー付き車両群や巨大なトランザクション基盤をゼロから構築しなければなりません。データの蓄積には時間がかかり(成熟まで18〜36か月程度を要するとの見方もあります (要検証))、その間に先行者はさらに先へ進みます。資金でモデルは買えても、過去に積み上がった固有データの時間そのものは買えない、という点が堀の本質です。
ネットワーク効果(データネットワーク効果)
ネットワーク効果(network effects) は、参加者が増えるほどサービスの価値が高まる現象です。AI と結びつくと、参加者の行動データがモデル精度を押し上げる**データネットワーク効果(data network effects)**として働きます。
何をしているか:TikTok は視聴・スキップ・再生時間といった細かな視聴シグナルを推薦アルゴリズムに即時反映し、ユーザーごとに最適化されたフィードを提供します。推薦精度が上がると滞在時間が伸び、滞在が増えるほど学習に使えるシグナルがさらに増えます。
なぜ競合が真似できないか:同等の規模・粒度・鮮度を持つ視聴シグナルは、相応のユーザー基盤がなければ集まりません。後発が同じアルゴリズムを実装できたとしても、それを賢くする「燃料」としてのデータ量と多様性で劣後します。価値とデータが相互に増幅する二重ループが、模倣の障壁になります。
組織コンテキスト・実行知
HBR が強調するのは、共有可能なモデルに対して、組織固有の**コンテキスト(context)と実行知(execution knowledge)**は共有できない、という非対称性です。同じ AI を使っても、業務文脈をどれだけ正確に反映できるかで成果が分かれます。
Context is demonstrated execution.
(HBR, 2026。和訳:コンテキストとは「実証された実行力」である、という趣旨です。机上の知識ではなく、現場で実際に回してきた実行の蓄積こそが文脈の正体だ、という指摘だと私は理解しています。)
何をしているか:先行企業は、自社の業務プロセス・顧客対応履歴・例外処理のノウハウといった暗黙知を構造化し、AI が参照・活用できる形に整えています。これにより、汎用モデルでは出せない自社特有の判断品質を引き出します。
なぜ競合が真似できないか:実行知は、長年の試行錯誤と現場の意思決定の積み重ねから生まれるため、文書を渡しただけでは移転できません。誰もが同じモデルを使える世界だからこそ、この「載せる文脈」の差が決定的な差になる、というのが HBR の論旨です。
統合とスイッチングコスト
統合(integration) によって自社サービスが顧客の業務やシステムに深く組み込まれると、乗り換えの手間とリスク、すなわち**スイッチングコスト(switching cost)**が高まり、これ自体が堀になります。
何をしているか:Stripe は決済処理だけでなく、開発者向け API・ダッシュボード・不正検知・会計連携などを一体で提供し、顧客の決済データとワークフローに深く統合されています。蓄積された決済データは不正検知 AI の精度向上にも還元されます。
なぜ競合が真似できないか:一度業務に組み込まれた決済基盤を別事業者へ移すには、再実装・再テスト・移行リスクが伴います。価格がわずかに安い競合が現れても、移行コストが上回る限り顧客は留まります。統合の深さがそのまま離脱のしにくさに変換される構造です。
独占・規制資産
最後の型は、ライセンス・規制・希少データへのアクセスといった**独占・規制資産(proprietary / regulatory assets)**です。誰もが取得できるわけではない資産に AI を載せると、参入障壁そのものが堀になります。
何をしているか:Tempus AI は臨床データとゲノムデータを大規模に保有し、それらを精密医療向けの解析に活用しています。Ferrovial のような有料道路事業者は、インフラの長期保有を通じて得られる交通データを動的課金(料金最適化)の機械学習に活かしています。
なぜ競合が真似できないか:規制・許認可・長期契約・希少な実データへのアクセスは、資金だけでは短期に複製できません。新規参入者が同等のデータ資産にたどり着くには、規制上の壁と時間という二重の障壁を越える必要があります。AI はその独占資産の価値を増幅する装置として働きます。
比較・代替手法
5つの堀の型を、メカニズム・代表企業・模倣難易度の観点で整理します。
| 堀の型 | メカニズム | 代表企業 | 模倣難易度 |
|---|---|---|---|
| データフライホイール | 利用→独自データ→改善→更なる利用の自己強化ループ | Tesla / Amazon | ○ 高(時間が必要) |
| ネットワーク効果 | 参加・行動が増えるほど推薦精度と価値が上がる | TikTok | ○ 高(規模が必要) |
| 組織コンテキスト・実行知 | 共有不能な業務文脈・実行知を AI に載せる | (業種を問わず) | ○ 高(移転困難) |
| 統合とスイッチングコスト | 業務への深い組込みで乗り換えコストを生む | Stripe | △ 中〜高 |
| 独占・規制資産 | 規制・希少データへの独占アクセスを AI で増幅 | Tempus AI / Ferrovial | ○ 高(規制障壁) |
代替手法として「AI ツールの早期大量導入」で先行する戦略も語られますが、ツール自体が共有財である以上、それ単独では持続的な優位になりにくいと私は考えます。導入スピードは初期の差を生んでも、上表の自己強化・移転困難・独占といった構造を伴わなければ、すぐに追いつかれます。
私の考察
私の判断軸は明確です。AI 導入それ自体を成果(ゴール)にしないこと、そして自社固有データ・実行知・統合に AI を載せて初めて堀になるという前提で投資を設計することです。モデルがコモディティ化した今、「AI を使えるか」ではなく「使うほど強くなる構造を自社が持てるか」を問うべきだと思います。
特に中堅・中小規模の組織にとっては、巨大プレイヤーのようなデータフライホイールを一から作るのは現実的でない場合が多いでしょう。その場合は、組織コンテキスト・実行知や、既存顧客への統合の深さといった、規模に依存しにくい型に注力するのが現実的だと考えます。どの型なら自社が勝てるかの見極めが、戦略の出発点になります。
参考リンク
関連する記事
AI 導入の現場 — 6 業界の代表ケースをアーキテクチャで読む
Morgan Stanley の RAG・BMW の予知保全・Walmart の在庫最適化・Mayo Clinic の連合学習・GitHub Copilot・Klarna の 6 業界事例を、採用技術と効果指標、アーキテクチャの観点から整理して解説します。

業務で言われる『AI』の実態 — LLM・RAG・エージェントの動作を図で理解
業務サイドが日々耳にする『AI 利活用』の中身を、LLM の入出力・RAG の知識補完・エージェントのツール実行という3つの構成要素に分解し、図とともに解説します。コールセンター・社内検索など複数業種の具体例を示し、過信せず使うための観点を整理します。
生成AI開発のセキュリティ:どこで何を守るか
生成AIを使った開発(Claude CodeやCursor等)でどこに何のセキュリティリスクが潜むかを、データフロー図で整理しました。プロンプトインジェクションや企業秘密の漏洩を、入力・出力・権限・量の4観点で多層に防ぐ設計をOWASP LLM Top 10とAWS IAM条件キーを交えて解説します。